" height="30.79999471128656px" id="oBuaKNVXh" width="97.89999596251637px"/></svg>)
X
Gaurang Kaushik

THE WORKFLOW ENVISIONS THE FOLLOWING
PHASE PIPELINE TO ESTABLISH THE FEASIBILITY OF THE PROPOSED NARRATIVE AND RESEARCH
PHASE - I
PHASE - II
PHASE - III
PHASE - IV
PHASE - I // IMAGE GENERATION
COMFYUI INTEGRATION
WHAT IS COMFYUI ?
ComfyUI is a powerful graphical user interface (GUI) designed specifically for Diffusion models and checkpoint workflows, it adopts a node-based approach that allows users to visually construct and customize their AI image generation pipelines through interconnected components.
POSSIBLE WORKFLOWS
PROMPT TO IMAGE GENERATION
TEXT BASED DESCRIPTION
EMBEDDINGS FOR THE IMAGE GENERATION
SKETCH TO IMAGE GENERATION
DEVELOPMENT OF ROUGH SKETCH
DESCRIPTION OF IMAGE TO GENERATE
IMAGE TO IMAGE GENERATION
BASE IMAGE FOR GENERATION OF RETENTION IMAGE
DEFINITION OF IMAGE BASED ON PROMPT
LORA TRAINING
PROMPT BASE LEARNING
SUBJECT BASE
THE NATURE OF IMAGE GENERATION AND ADAPTATION
Image generation through Generative AI comes with a challenge and goal of 'CONTROL' , how can the degree of randomness be controlled to follow a consistent style and language, this can be achieved through Low-Rank (LoRa) Adaptation Models, which is trained on images following a style with triggers and embeddings to activate the LoRa in the workflow.
LoRa TRAINING // 'The GKMDL Model'

The Low Rank Adaptation - GKMDL Model is trained on Flux Dev model by Black Forest Labs, with over 80 Design Samples embedded with their description and triggers, this aids the workflow in generation and create images following the style and language required for the development of the research, namely Timber Shell Structures.
THE RESULTS AND GENERATION
BASE MODEL - Flux Dev. ; LoRa Weight - 1.15 ; Steps - 20 ; Sampler - DPMMP_2M
The COMFYUI workflow is made to run with the integration of the trained LoRa weights , paired with the prompts, the generated output follow a consistency of style adhering to the requirement of the user and the research.
WHAT IS COMFYUI ?
ComfyUI is a powerful graphical user interface (GUI) designed specifically for Diffusion models and checkpoint workflows, it adopts a node-based approach that allows users to visually construct and customize their AI image generation pipelines through interconnected components.
POSSIBLE WORKFLOWS
PROMPT TO IMAGE GENERATION
TEXT BASED DESCRIPTION
EMBEDDINGS FOR THE IMAGE GENERATION
SKETCH TO IMAGE GENERATION
DEVELOPMENT OF ROUGH SKETCH
DESCRIPTION OF IMAGE TO GENERATE
IMAGE TO IMAGE GENERATION
BASE IMAGE FOR GENERATION OF RETENTION IMAGE
DEFINITION OF IMAGE BASED ON PROMPT
LORA TRAINING
PROMPT BASE LEARNING
SUBJECT BASE
THE NATURE OF IMAGE GENERATION AND ADAPTATION
Image generation through Generative AI comes with a challenge and goal of 'CONTROL' , how can the degree of randomness be controlled to follow a consistent style and language, this can be achieved through Low-Rank (LoRa) Adaptation Models, which is trained on images following a style with triggers and embeddings to activate the LoRa in the workflow.
LoRa TRAINING // 'The GKMDL Model'
The Low Rank Adaptation - GKMDL Model is trained on Flux Dev model by Black Forest Labs, with over 80 Design Samples embedded with their description and triggers, this aids the workflow in generation and create images following the style and language required for the development of the research, namely Timber Shell Structures.
THE RESULTS AND GENERATION
BASE MODEL - Flux Dev. ; LoRa Weight - 1.15 ; Steps - 20 ; Sampler - DPMMP_2M
The COMFYUI workflow is made to run with the integration of the trained LoRa weights , paired with the prompts, the generated output follow a consistency of style adhering to the requirement of the user and the research.
WHAT IS COMFYUI ?
ComfyUI is a powerful graphical user interface (GUI) designed specifically for Diffusion models and checkpoint workflows, it adopts a node-based approach that allows users to visually construct and customize their AI image generation pipelines through interconnected components.
POSSIBLE WORKFLOWS
PROMPT TO IMAGE GENERATION
TEXT BASED DESCRIPTION
EMBEDDINGS FOR THE IMAGE GENERATION
SKETCH TO IMAGE GENERATION
DEVELOPMENT OF ROUGH SKETCH
DESCRIPTION OF IMAGE TO GENERATE
IMAGE TO IMAGE GENERATION
BASE IMAGE FOR GENERATION OF RETENTION IMAGE
DEFINITION OF IMAGE BASED ON PROMPT
LORA TRAINING
PROMPT BASE LEARNING
SUBJECT BASE
THE NATURE OF IMAGE GENERATION AND ADAPTATION
Image generation through Generative AI comes with a challenge and goal of 'CONTROL' , how can the degree of randomness be controlled to follow a consistent style and language, this can be achieved through Low-Rank (LoRa) Adaptation Models, which is trained on images following a style with triggers and embeddings to activate the LoRa in the workflow.
LoRa TRAINING // 'The GKMDL Model'
The Low Rank Adaptation - GKMDL Model is trained on Flux Dev model by Black Forest Labs, with over 80 Design Samples embedded with their description and triggers, this aids the workflow in generation and create images following the style and language required for the development of the research, namely Timber Shell Structures.
THE RESULTS AND GENERATION
BASE MODEL - Flux Dev. ; LoRa Weight - 1.15 ; Steps - 20 ; Sampler - DPMMP_2M
The COMFYUI workflow is made to run with the integration of the trained LoRa weights , paired with the prompts, the generated output follow a consistency of style adhering to the requirement of the user and the research.
WHAT IS COMFYUI ?
ComfyUI is a powerful graphical user interface (GUI) designed specifically for Diffusion models and checkpoint workflows, it adopts a node-based approach that allows users to visually construct and customize their AI image generation pipelines through interconnected components.
POSSIBLE WORKFLOWS
PROMPT TO IMAGE GENERATION
TEXT BASED DESCRIPTION
EMBEDDINGS FOR THE IMAGE GENERATION
SKETCH TO IMAGE GENERATION
DEVELOPMENT OF ROUGH SKETCH
DESCRIPTION OF IMAGE TO GENERATE
IMAGE TO IMAGE GENERATION
BASE IMAGE FOR GENERATION OF RETENTION IMAGE
DEFINITION OF IMAGE BASED ON PROMPT
LORA TRAINING
PROMPT BASE LEARNING
SUBJECT BASE
THE NATURE OF IMAGE GENERATION AND ADAPTATION
Image generation through Generative AI comes with a challenge and goal of 'CONTROL' , how can the degree of randomness be controlled to follow a consistent style and language, this can be achieved through Low-Rank (LoRa) Adaptation Models, which is trained on images following a style with triggers and embeddings to activate the LoRa in the workflow.
LoRa TRAINING // 'The GKMDL Model'
The Low Rank Adaptation - GKMDL Model is trained on Flux Dev model by Black Forest Labs, with over 80 Design Samples embedded with their description and triggers, this aids the workflow in generation and create images following the style and language required for the development of the research, namely Timber Shell Structures.
THE RESULTS AND GENERATION
BASE MODEL - Flux Dev. ; LoRa Weight - 1.15 ; Steps - 20 ; Sampler - DPMMP_2M
The COMFYUI workflow is made to run with the integration of the trained LoRa weights , paired with the prompts, the generated output follow a consistency of style adhering to the requirement of the user and the research.

























PHASE - II // IMAGE TO 3D MESH
LARGE RECONSTRUCTION MODELS
WHAT ARE LRMs ?
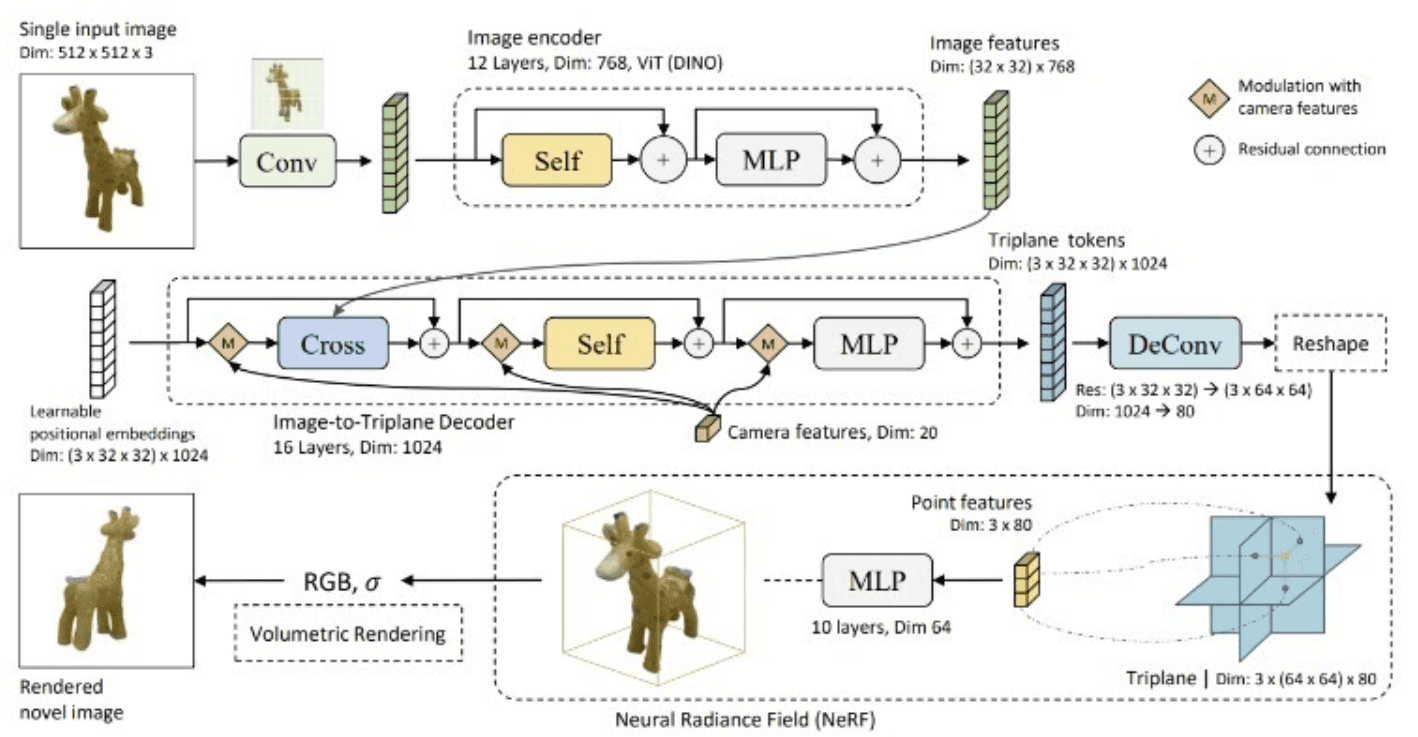
Large Reconstruction Models (LRMs) are deep learning models, typically transformer-based, that are trained to reconstruct 3D objects from 2D images. They learn complex 3D representations from vast datasets of 3D objects and their corresponding 2D views. LRMs can generate 3D models from single images, multiple images, or even text descriptions.
STATE OF THE ART MODELS

“ DEPTH BASE ENCLOSURE FOR VOLUMETRIC UNDERSTANDING AND MODELS ADAPTATION FOR A SIMPLE GEOMETRY ”
Click to see how models performed !
TRELLIS 3D GENERATION
TRELLIS 3D
A native 3D generative model built on a unified Structured Latent representation and Rectified Flow Transformers, enabling versatile and high-quality 3D asset creation.
LINK : Research Paper
Citation : Sasaki, Shun, and Erik Niklasson. 2024. Architectural Design in the Age of Generative AI: Between Images and Material Realities. arXiv. https://arxiv.org/abs/2412.01506
ASSET GENERATION LAYOUT - IMAGE // GLB // 3D VISUAL



WHAT ARE LRMs ?
Large Reconstruction Models (LRMs) are deep learning models, typically transformer-based, that are trained to reconstruct 3D objects from 2D images. They learn complex 3D representations from vast datasets of 3D objects and their corresponding 2D views. LRMs can generate 3D models from single images, multiple images, or even text descriptions.
STATE OF THE ART MODELS
“ DEPTH BASE ENCLOSURE FOR VOLUMETRIC UNDERSTANDING AND MODELS ADAPTATION FOR A SIMPLE GEOMETRY ”
Click to see how models performed !
TRELLIS 3D GENERATION
TRELLIS 3D
A native 3D generative model built on a unified Structured Latent representation and Rectified Flow Transformers, enabling versatile and high-quality 3D asset creation.
LINK : Research Paper
Citation : Sasaki, Shun, and Erik Niklasson. 2024. Architectural Design in the Age of Generative AI: Between Images and Material Realities. arXiv. https://arxiv.org/abs/2412.01506
ASSET GENERATION LAYOUT - IMAGE // GLB // 3D VISUAL
WHAT ARE LRMs ?
Large Reconstruction Models (LRMs) are deep learning models, typically transformer-based, that are trained to reconstruct 3D objects from 2D images. They learn complex 3D representations from vast datasets of 3D objects and their corresponding 2D views. LRMs can generate 3D models from single images, multiple images, or even text descriptions.
STATE OF THE ART MODELS
“ DEPTH BASE ENCLOSURE FOR VOLUMETRIC UNDERSTANDING AND MODELS ADAPTATION FOR A SIMPLE GEOMETRY ”
Click to see how models performed !
TRELLIS 3D GENERATION
TRELLIS 3D
A native 3D generative model built on a unified Structured Latent representation and Rectified Flow Transformers, enabling versatile and high-quality 3D asset creation.
LINK : Research Paper
Citation : Sasaki, Shun, and Erik Niklasson. 2024. Architectural Design in the Age of Generative AI: Between Images and Material Realities. arXiv. https://arxiv.org/abs/2412.01506
ASSET GENERATION LAYOUT - IMAGE // GLB // 3D VISUAL
WHAT ARE LRMs ?
Large Reconstruction Models (LRMs) are deep learning models, typically transformer-based, that are trained to reconstruct 3D objects from 2D images. They learn complex 3D representations from vast datasets of 3D objects and their corresponding 2D views. LRMs can generate 3D models from single images, multiple images, or even text descriptions.
STATE OF THE ART MODELS
“ DEPTH BASE ENCLOSURE FOR VOLUMETRIC UNDERSTANDING AND MODELS ADAPTATION FOR A SIMPLE GEOMETRY ”
Click to see how models performed !
TRELLIS 3D GENERATION
TRELLIS 3D
A native 3D generative model built on a unified Structured Latent representation and Rectified Flow Transformers, enabling versatile and high-quality 3D asset creation.
LINK : Research Paper
Citation : Sasaki, Shun, and Erik Niklasson. 2024. Architectural Design in the Age of Generative AI: Between Images and Material Realities. arXiv. https://arxiv.org/abs/2412.01506
ASSET GENERATION LAYOUT - IMAGE // GLB // 3D VISUAL
PHASE - III // MESH REFINEMENT
MESH EXTRACTION AND WORKABILITY
MESHES
MESH COMPLEXITIES

REFINED MESH PHASES

BASE MESH

MESHES
MESH COMPLEXITIES
REFINED MESH PHASES
BASE MESH
MESHES
MESH COMPLEXITIES
REFINED MESH PHASES
BASE MESH
MESHES
MESH COMPLEXITIES
REFINED MESH PHASES
BASE MESH






PHASE - IV // FABRICATION MEANS
JOINERIES AND PROFILE DEVELOPMENT

GENERATED MESH GEOMETRY NESTED TO CNC PROFILING THE PIECES AND MARKING




CONNECTION LOGIC
Planar Elements Joinery between panels
Aid of connecting member plate between components to create a bespoke joint and connection. The joint would adapt to the planarity of the faces and form a joint morphing the two planar blocks.